在这里大致记录下我在ubuntu 14.04系统下对tensorflow使用,先挖个坑在这儿。
1. 说明和参考资料
1.1 阿里田丰谈人工智能
在等待mnist demo完成过程中,看了下阿里云的云大学,田丰谈人工智能。核心观点:
- 生物进化与人工智能的进步都源于试错;
- 智能设备的中控应该是语音,而不是智能路由器、客厅电脑这些,因为人都懒;
- 莱布尼茨认为未来应该是:计算代替思考,比如会计之间的讨论就可以用数据说话;
- 个体智能在终端上/全局智能在云端:终端计算可以有效避免长延时的网络,降低功耗;
- 数据为书/机器为师:机器学习的书是数据,大量数据的分析;人们可能会以机器为老师;
- AI飞轮(功能-数据-模型-用户),用户的反馈和体验是推动AI飞轮持续演进的关键;
- 《技术的本质》:复杂迭代的进步、数据为王还是算法为王?短期内是数据重要,长远算法是关键,计算也非常重要;
- MIT和阿里出了一本书:《科技之巅》:语音入口/万物挑战(借助网络实现机器人教机器人)/特斯拉的autopilot2.0融入了GPU/数据安全/灵巧性机器人/杭州城市大脑。
1.2 参考资料
- Google tensorflow的官网:https://www.tensorflow.org/
- 知乎上对tensorflow的讨论:https://www.zhihu.com/question/49909565
- duanshishi同学的tensorflow入门系列:http://hacker.duanshishi.com/?p=1639
- 可以在树莓派3B上运行的tensorflow,分为直接pip安装和源码安装两部分:https://github.com/samjabrahams/tensorflow-on-raspberry-pi
- 阿里云上利用docker做容器搭建tensorflow框架:https://yq.aliyun.com/articles/60601?spm=5176.100239.blogcont60894.12.jIWEuE
- 在树莓派的GPU上映射DBN,对于加速tensorflow的GPU映射有参考:https://petewarden.com/2014/08/07/how-to-optimize-raspberry-pi-code-using-its-gpu/
- 让机器人能“看懂”世界:https://www.oreilly.com/learning/how-to-build-a-robot-that-sees-with-100-and-tensorflow
- 2015年增强了深度信息的AlexNet材料:http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf
- 斗大的熊猫做的基于RNN深度学习网络的聊天机器人:http://blog.topspeedsnail.com/archives/10735
- 斗大的熊猫用thchs30的数据库做中文语音识别:http://blog.topspeedsnail.com/archives/10696
1.3 参考文献
2. 安装与初步测试
2.1 针对x86系统的安装
(该方案同样适用于在阿里云ECS服务器上的安装,但需要先更新下阿里云的pip源)如下:
sudo apt-get install python-dev python-pipexport TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.10.0-cp27-none-linux_x86_64.whlsudo pip install --upgrade $TF_BINARY_URL
说明下:之所以不直接pip install tensorflow,是因为有时候pip的源里面还没有tensorflow,会报找不到tensorflow的错误。下面用官方的例子简单测试下:
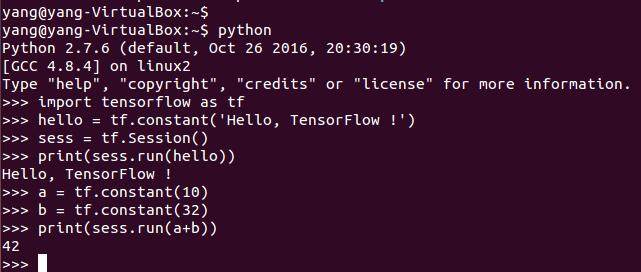
嗯,至少安装是成功的,后半部分的计算,比较类似matlab了。
2.2 针对有nvidia gpu的简单系统安装
等待我们i7+GTX1080 SLI的服务器到货,再来讨论这部分,特别是SLI的GPU貌似不太容易安装。
2.3 针对x86系统从源码开始编译安装
很简单,也就几步:1)git得到源码;2)安装google自己用的build工具bazel;3)用bazel编译安装tensorflow
git clone https://github.com/tensorflow/tensorflow
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installerecho "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.listcurl https://bazel.build/bazel-release.pub.gpg | sudo apt-key add -sudo apt-get update && sudo apt-get install bazel sudo apt-get upgrade bazel sudo apt-get remove bazel mkdir bazel/ cd bazel/ wget https://github.com/bazelbuild/bazel/releases/download/0.4.4/bazel-0.4.4-installer-linux-x86_64.sh chmod +xbazel-0.4.4-installer-linux-x86_64.sh ./bazel-0.4.4-installer-linux-x86_64.sh --user echo "export PATH=$PATH:~/bin" > ~/.bashrc source ~/.bashrc sudo apt-get install python-numpy python-dev python-wheel cd ../
cd tensorflow/ ./configure bazel build -c opt //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
我在虚拟机里面安装,配置为:3核i7 6700K@4GHz,4GB内存,SSD,11:33开始configure,11:37完成配置(有error),然后开始编译,12:00左右完成,大约20分钟。12:44开始生成安装包,瞬间生成。最后安装生成的包,大约2分钟。
2.4 针对树莓派3B系统的简单安装
在树莓派3B的很多版本都可以正常安装,如下:
sudo apt-get install python-dev python-pip python-numpy
wget https://github.com/samjabrahams/tensorflow-on-raspberry-pi/releases/download/v0.11.0/tensorflow-0.11.0-cp27-none-linux_armv7l.whl
sudo pip install tensorflow-0.11.0-cp27-none-linux_armv7l.whl
2.5 针对ARM系统从源码开始编译安装
据说整个安装时间需要几个小时,暂时没有做。
2.6 在我们自己R16/R18上安装
3. 找几个例子跑一下
3.1 官方简单的手写数字识别
(跑简单例子时,上述安装都可以跑,还可以测试下性能的区别)官网接着说:可以试着跑跑几个demo model,所有的model都安装在:
/usr/local/lib/python2.7/dist-packages/tensorflow
第一个简单的demo是便是手写的数字,用到的测试集是经典的MNIST dataset。该demo在:
/usr/local/lib/python2.7/dist-packages/tensorflow/models/image/mnist/convolutional.py
简单跑跑看,直接运行python /path/to/convolutional.py
虚拟机环境(分配了3核i7 6700K,3GB的内存,虚拟化全开)。23:05开始跑,会首先自动下载一堆的训练集和测试集数据到~/data/ 目录下面,网速慢的同学要多等等(23:10分结束下载,下载了12MB左右的数据)。

然后就开始训练了,训练过程中python占了78%~260%的CPU资源,大部分时候还是78%左右。训练过程中,minibatch会不断给出minibatch error和validation error,前者变化比较大0%~3%左右,后者则长时间在2%以内,每100次迭代大约150ms。learning rate从1700次迭代后开始下降。最终在23:32完成(总计22分钟左右),最终结果如下:
yang@yang-VirtualBox:~$ python /usr/local/lib/python2.7/dist-packages/tensorflow/models/image/mnist/convolutional.py Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes. Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes. Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes. Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes. Extracting data/train-images-idx3-ubyte.gz Extracting data/train-labels-idx1-ubyte.gz Extracting data/t10k-images-idx3-ubyte.gz Extracting data/t10k-labels-idx1-ubyte.gz Initialized! Step 0 (epoch 0.00), 2.0 ms Minibatch loss: 8.334, learning rate: 0.010000 Minibatch error: 85.9% Validation error: 84.6% Step 100 (epoch 0.12), 151.4 ms Minibatch loss: 3.250, learning rate: 0.010000 Minibatch error: 6.2% Validation error: 7.6% Step 200 (epoch 0.23), 150.3 ms Minibatch loss: 3.377, learning rate: 0.010000 Minibatch error: 12.5% Validation error: 4.2% ========================== Step 1800 (epoch 2.09), 149.3 ms Minibatch loss: 2.660, learning rate: 0.009025 Minibatch error: 3.1% Validation error: 1.3% Step 1900 (epoch 2.21), 151.7 ms Minibatch loss: 2.636, learning rate: 0.009025 Minibatch error: 1.6% Validation error: 1.2% ============================ Minibatch loss: 2.130, learning rate: 0.007738 Minibatch error: 0.0% Validation error: 1.1% Step 4500 (epoch 5.24), 153.7 ms Minibatch loss: 2.201, learning rate: 0.007738 Minibatch error: 4.7% Validation error: 1.1% ============================== Step 8400 (epoch 9.77), 147.6 ms Minibatch loss: 1.596, learning rate: 0.006302 Minibatch error: 0.0% Validation error: 0.8% Step 8500 (epoch 9.89), 151.6 ms Minibatch loss: 1.618, learning rate: 0.006302 Minibatch error: 0.0% Validation error: 0.9% Test error: 0.8%
基本使用部分,google说(Tensorflow的核心表达):tensorflow是把计算表示为图(图中的node就表示ops,每个ops都会对不定数目个Tensor做运算,一般来说tensor都是多维数组),然后通过Sessions去执行这些图,将数据表示为tensor,并用Variables维持状态。
3.2 davidsandberg的人脸识别
- git源在这里(目前版本匹配Tensorflow r0.12版本):https://github.com/davidsandberg/facenet.git
- 论文引用在这里:https://arxiv.org/abs/1503.03832
在ubuntu上直接:
git clone https://github.com/davidsandberg/facenet.git cd facenet/
看文档感觉比较麻烦,后面再来看怎么运行。
3.3 图像识别inception应用
git clone https://github.com/tensorflow/models.git cd models/tutorials/image/imagenet/ python classify_image.py
就开始下载训练和测试所需的data, 第二次运行就无需下载data了,可以测试下性能,如下:
time python classify_image.py
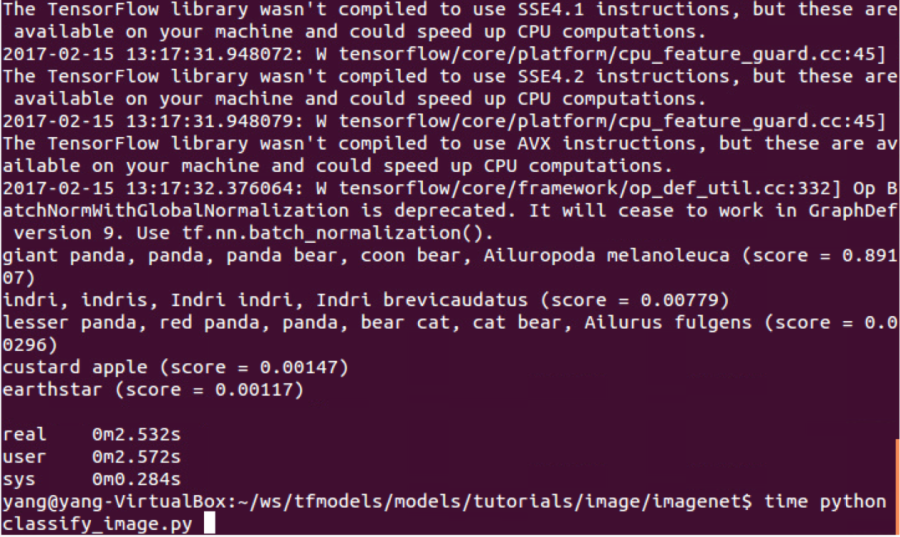
大约2.5s完成,这包括模型的加载、预测算法运行以及打印信息(很可能模型加载耗时很多)。下面,我们对比下同一张雨伞图片(如下)在ubuntu虚拟机和树莓派3B上运行的精度和速度:

time python classify_image.py --image_file=QQ20170215-0.jpg
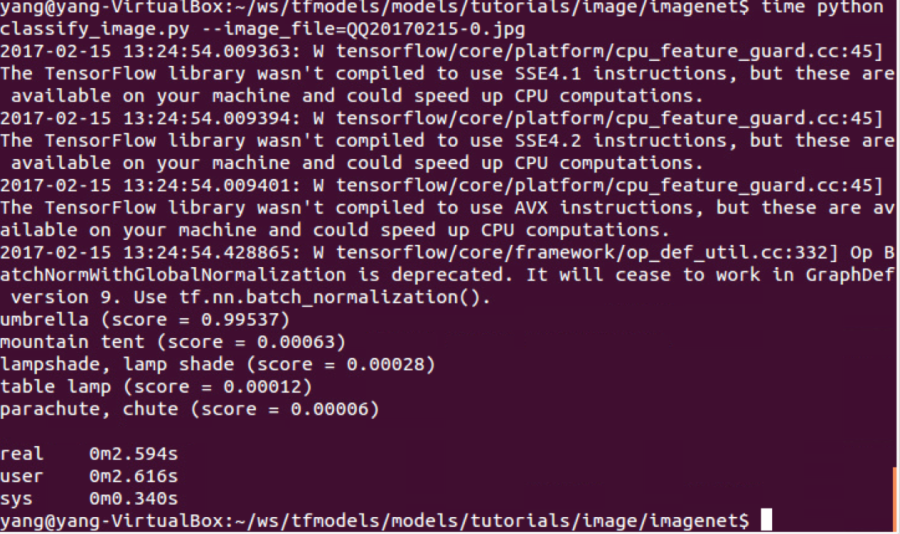
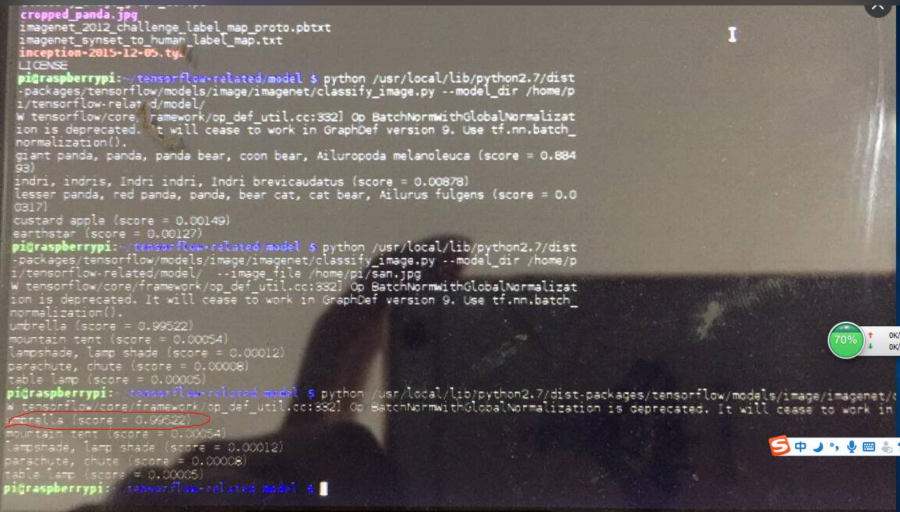
精度上不同架构运行的结果差不多,都是伞为0.99以上的score。速度上区别就大了,i7虚拟机上是2.5s左右(注意单张辨识和此前实验的16张辨识时间差不多,也就是真正辨识的开销可能非常小)。而树莓派3B上花了48s。
网上也有同学用树莓派3B测试过,他们的速度大约是50s,和我们差不多。而他们指出:很多时间是花在模型本身的加载上(估计虚拟机版本的2.x s也都是花在了模型加载上),可以通过预加载模型的方式加速(可以加速到4.2s/张识别),参考这里。
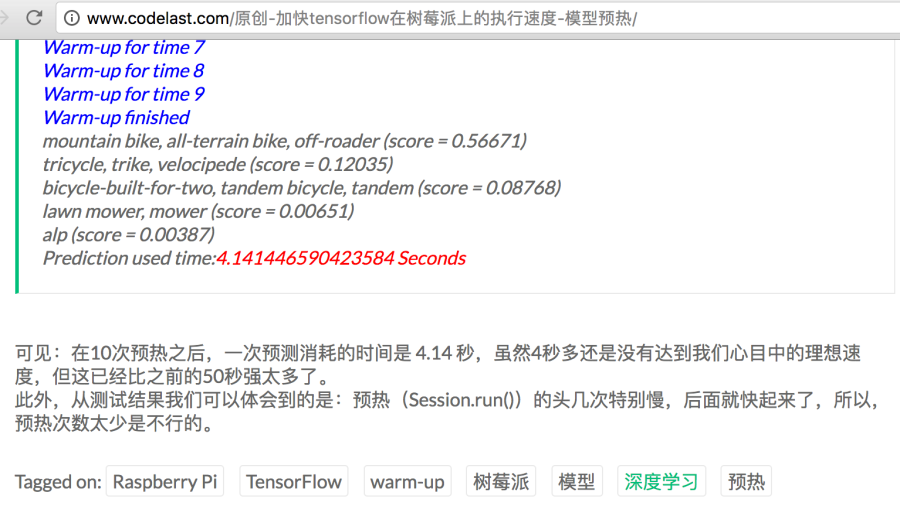
与性能相关的问题,我们在第4节性能分析中展开讨论。
3.4 语音识别
4. 性能分析
本小节分别讨论tensorflow架构不同模型在不同架构上的运行性能,能效比较难测算,暂时不考虑(我们准备引入tensorflow的官方benchmark做测试)。
4.1 基于inception的性能比较
可以参考这里,有一个不同架构下运行tensorflow的inceptionv3的性能数据,如下:
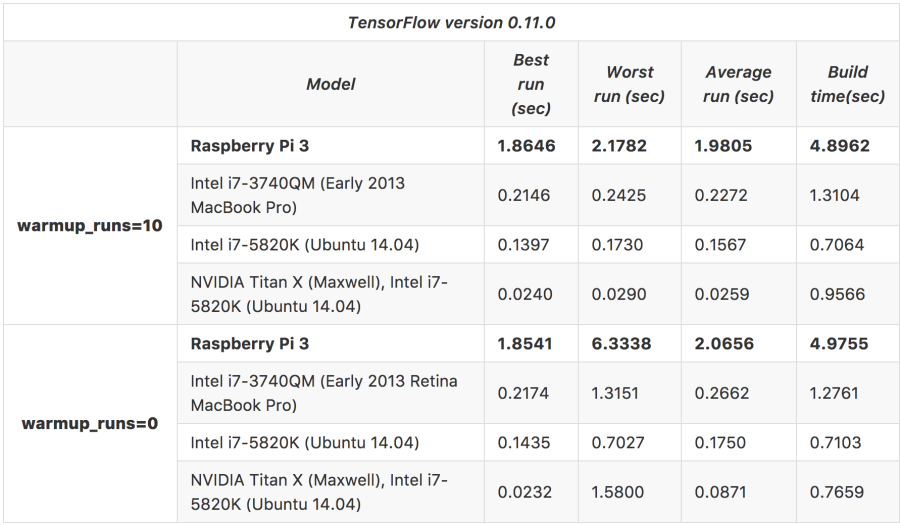
从上面这张表可以看出(注意所有数据都是:成批的运行,不是单张图片的预测):
- 上述比较包含两个大维度,即有warmup和没有warmup过程。总的来说,无论是台式机(包含/不包含GPU),还是树莓派,这两种情况的平均性能差异并不大,但worst case的差异却非常可观;
- 相同情况下,GPU加速版本,6核i7、4核早期低功耗架构i7、4核ARM Cortex-A53的性能比大约是(warmup=10的平均值):77:12:9:1。GPU的效率非常可观,Cortex-A53比i7差距也接近10倍;
- 从build时间来看,调用GPU的确会引入一定的开销,但相对于收益非常合算。
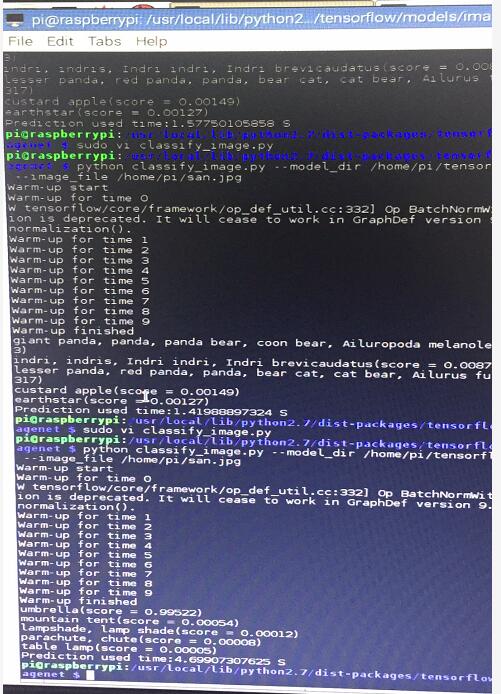
补充一张我们自己运行出来的数据:
4.2 官方benchmark运行
bazel build --config opt tensorflow/tools/benchmark:benchmark_model
bazel-bin/tensorflow/tools/benchmark/benchmark_model \ --graph=tensorflow_inception_graph.pb \ --input_layer="input:0" \ --input_layer_shape="1,224,224,3" \ --input_layer_type="float" \ --output_layer="output:0"
5. 我们可以干嘛
我们最终需要在机器人身上完成至少三方面的深度学习工作,分别是:
- 图片/视频的物理识别、人脸识别;
- 自然语音的本地识别(还不清楚能否完成):
- 先进运动控制。
